Nicola FanelliI am a PhD student in Computer Science & Mathematics in the Department of Computer Science at the University of Bari Aldo Moro, where I work on computer vision and deep learning, under the supervision of Prof. Giovanna Castellano and Prof. Gennaro Vessio. I am currently pursuing a PhD funded by a PhD fellowship within the framework of the Italian "D.M. n. 118/23" under the PNRR, Mission 4, Component 1, Investment 4.1 on the PhD project "Analysis and Valorization of Digitized Artistic Heritage using Artificial Intelligence techniques". I am currently working in the CILab lab. In 2023, I obtained my Master's degree in Computer Science (AI curriculum) from the University of Bari Aldo Moro, with a focus on machine learning. During the Master's program, I completed numerous ML projects related to computer vision and NLP, culminating in my thesis on automatic artwork captioning. I also collaborated for four months with the National Research Council of Italy, where I extended my BSc thesis work on text complexity assessment with machine learning. Email / GitHub / Google Scholar / LinkedIn / StackOverflow / Medium / Twitter |

|
News |
|
October 2025: I have been invited as a reviewer for CVPR 2026, one of the premier conferences in the field of computer vision. I am excited to contribute to the peer-review process and engage with cutting-edge research in computer vision! 🖼️🤖 |
|
September 2025: I have joined the University of Zurich as a visiting researcher at the Digital Society Initiative (DSI) for six months, under the supervision of Dr. Eva Cetinić. I look forward to fruitful collaborations and new experiences in Switzerland! 🇨🇭 |
|
July 2025: Our work Label Anything was accepted at ECAI 2025 in Bologna! 🍝🇮🇹 |
|
July 2025: Our work I Dream My Painting received the Best Paper Honorable Mention by the IEEE Computational Intelligence Society (CIS) Italy Chapter at IJCNN 2025 in Rome! 🇮🇹 |
|
October 2024: Our work I Dream My Painting was accepted at WACV 2025 in Tucson, Arizona! 🌵🇺🇸 |
|
August 2024: Our work Art2Mus was accepted at the AI4VA Workshop at ECCV 2024 in Milan! 🇮🇹 |
|
July 2024: Our work Converso was accepted at the LUHME Workshop at ECAI 2024 in Santiago de Compostela! 🇪🇸 |
|
July 2024: I attended DeepLearn 2024 in Porto, learning about the latest advancements in deep learning. 🇵🇹 |
|
July 2024: I attended ICVSS 2024 in Sicily, where I had the chance to meet and learn from some of the most prominent researchers in computer vision! 🌞🇮🇹 |
|
October 2023: I started my PhD in Computer Science & Mathematics at the University of Bari Aldo Moro, where I will work on computer vision and deep learning! 👁️🤖 |
|
September 2023: Our work on artwork captioning was accepted at the FAPER Workshop at ICIAP 2023 in Udine! 🇮🇹 |
|
July 2023: I defended my Master’s thesis in Deep Learning at the University of Bari Aldo Moro! |
ResearchI'm interested in computer vision, multimodal deep learning (particularly vision and language), and generative models (MLLMs and diffusion models), especially in the context of artwork analysis. |

|
ArtSeek: Deep artwork understanding via multimodal in-context reasoning and late interaction retrievalNicola Fanelli, Gennaro Vessio, Giovanna Castellano ArXiv, 2025 paper / code / We present ArtSeek, a multimodal pipeline for image captioning and visual question answering (VQA) in the art domain. ArtSeek introduces a novel approach for multimodal retrieval by extending ColQwen2, a new dataset of multimodal fragments from Wikipedia (WikiFragments), a new multitask classification framework, and unlocks multimodal agentic RAG capabilities for multimodal LLMs via in-context learning. |
|
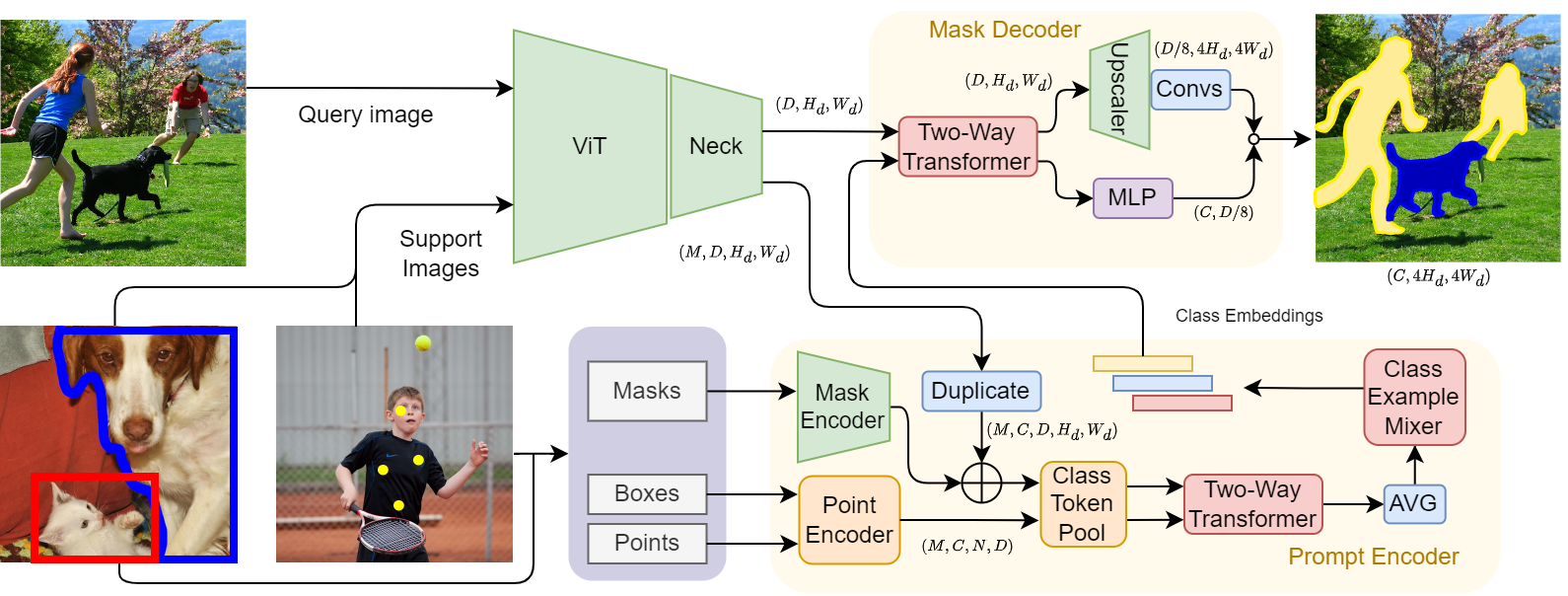
Label Anything: Multi-Class Few-Shot Semantic Segmentation with Visual PromptsPasquale De Marinis, Nicola Fanelli, Raffaele Scaringi, Emanuele Colonna, Giuseppe Fiameni, Gennaro Vessio, Giovanna Castellano European Conference on Artificial Intelligence (ECAI), 2025 paper / code / website / We present Label Anything, an innovative neural network architecture designed for few-shot semantic segmentation (FSS). Label Anything supports multi-class segmentation with points, boxes, or masks as prompts and relaxes multiple constraints in support set creation for FSS. |
|
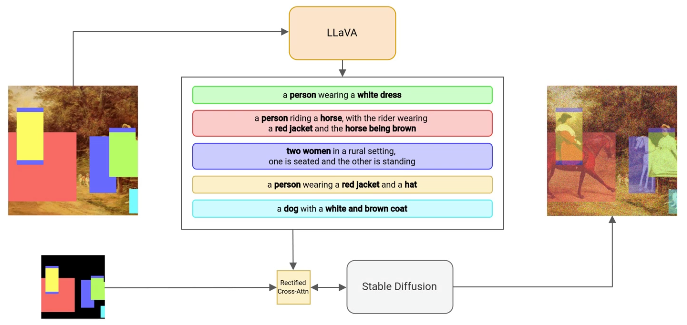
I Dream My Painting: Connecting MLLMs and Diffusion Models via Prompt Generation for Text-Guided Multi-Mask InpaintingNicola Fanelli, Gennaro Vessio, Giovanna Castellano IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025 paper / code / website / We inpaint multiple image regions, each with a different text prompt, and generate multi-mask prompt suggestions. |

|
Art2Mus: Bridging Visual Arts and Music through Cross-Modal GenerationIvan Rinaldi, Nicola Fanelli, Giovanna Castellano, Gennaro Vessio European Conference on Computer Vision (ECCV) Workshops, 2024 paper / code / We extend the AudioLDM2 architecture to generate music from artworks on a dataset of image-music pairings collected using ImageBind. |

|
Converso: Improving LLM Chatbot Interfaces and Task Execution via Conversational FormsGianfranco Demarco, Nicola Fanelli, Gennaro Vessio, Giovanna Castellano European Conference on Artificial Intelligence (ECAI) Workshops, 2024 paper / code / We develop a fully-containerized architecture for creating LLM chatbots and improve their performances in data acquisition with conversational forms. |

|
Exploring the Synergy Between Vision-Language Pretraining and ChatGPT for Artwork Captioning: A Preliminary StudyGiovanna Castellano, Nicola Fanelli, Raffaele Scaringi, Gennaro Vessio International Conference on Image Analysis and Processing (ICIAP) Workshops, 2023 paper / code / We explore caption generation for digitized artworks using a noisy dataset of LLM-generated descriptions. We introduce CLIPScore weighting to weigh the importance of each caption based on its quality to improve performances. |
|
Design and source code from Jon Barron's website |